
Gobblin 是 Hadoop 通用数据摄取框架,可以从各种数据源中提取,转换和加载海量数据。比如:数据库,rest APIs,filers,等等。Gobblin 处理日常规划任务需要所有数据摄取 ETLs,包括作业/任务规划,任务分配,错误处理,状态管理,数据质量检测,数据发布等等。
Gobblin 通过同样的执行框架从不同数据源摄取数据,在同一个地方管理所有不同数据源的元数据。同时结合了其他特性,比如自动伸缩,容错,数据质量保证,可扩展和处理数据模型改革等等。Gobblin 变得更容易使用,是个高效的数据摄取框架。
系统框架与组件
一个Gobblin的Job就是从数据源抽取数据到Sink(比如HDFS)。一个Job可由多个workunits或者tasks组成,他们代表一系列需要做的工作,如抽取抽取(Extracter),转换(Converter),写(Writer)等

Source
Source负责将整个工作分成多个workunit,并且为每个workunit制定抽取器(Extractor,暂且这么翻译吧)。类似于Hadoop的InputFormat。
Extractor
workunit中真正进行数据抽取。Gobblin使用一个watermark对象来告诉extractor数据的起始(low watermark)和结束位置(high watermark)。例如对于Kafka,watermarks就是一个partition的offsets。watermark不一定非得是数字numeric,只要可以被识别就行。
Writer
将通过record-level策略的记录写到临时目录(staging directory),整个task成功完成后再把所有记录移动到Writer输出目录(output directory)已接受task-level的质量检查,然后被Publisher发布出去。
Publisher
将writer写好的数据发布到Job输出目录。 Gobblin提供两种发布策略,完整提交和部分提交,部分提交时,只要writer输出目录中有不完整的数据也会被发布。
*Fork *
Gobblin支持将task流进行“分叉”操作,每一个抽取到的数据可以可以被不同的分支处理,每一个分支还可以有Converter,Quality Checker,writer和publisher。不同的分支可以把一条记录发布到不同的地方,或者以不同的格式发布到同一个地方。 见下图: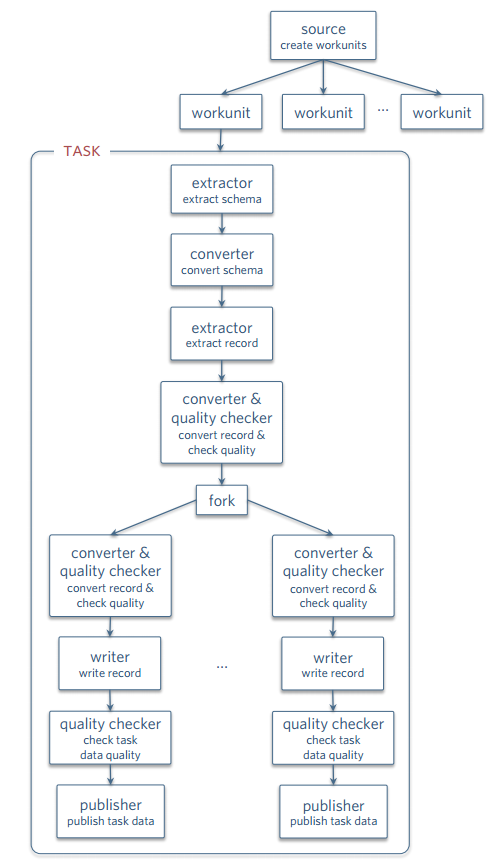
状态管理(State Store)
state store也叫metastore,用来管理整个Job执行过程中的状态。
watermark,schema等状态信息会被持久化到文件中,尤其对于watermark,这样下次重启时就可以知道上一次运行执行到哪一块。
之前测试的时候可被害苦了,每次从kafka中读数据,只有第一次执行job时才能读到,后来才发现因为这State Store里记录了上次从kafka中已经读完所有消息,因此第二次执行就不会去读消息了。
Gobblin默认存成Hadoop的Sequence file,Job每次执行产生一个文件,一个Job会有一个目录。每次任务启动都会先读上一次执行产生的文件。Gobblin也允许已插件的形式实现自己的状态管理,通过配置文件指定就可以。
Job执行
gobblin-runtime包负责Job/task的调度,状态管理,失败处理,监控等。
出差处理:
对于Job失败,Gobblin会记录出错次数,还有可选的发邮件功能。
对于task失败,会自动重试,最大重试次数可以通过配置文件配置。还有一个可选功能,启用之后,如果一个task经过所有重试后还是没有成功,会在Job下一次运行重新执行所有跟这个task相关的workunit,这对间歇性的数据不可用情况比较有用。
任务调度:
Gobblin内置一个基于Quartz的调度器,同时还支持Oozie, Azkaban, Chronos等。
整理去重 Compaction
提供两个现成的compactor,一种基于Hive,一种基于MapReduce。可以用来把小文件merge成大文件,过程中还可以去重。
部署
现在Gobblin支持standalone和MR两种部署模式,这里主要解读下MR模式吧。
Hadoop MapReduce Architecture
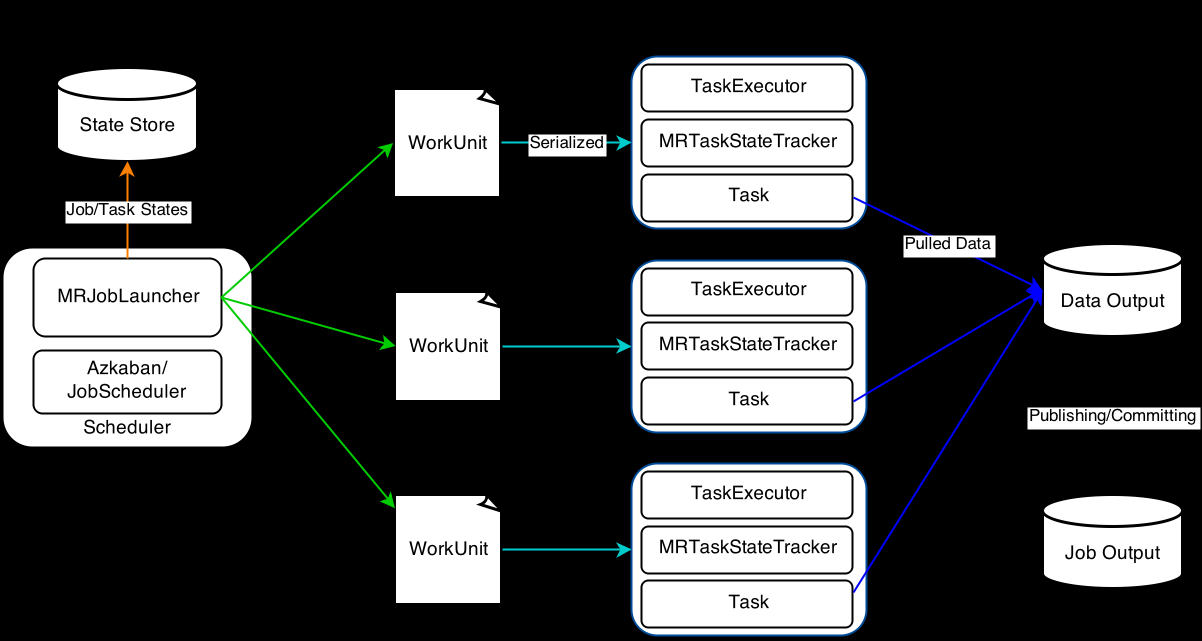
一个gobblin job只启动一个Map job, 用mappers当成Gobblin tasks的containers,这种设计方便与Yarn集成。跟单机模式不同,task retry依赖于Hadoop MR。
在这种模式下,一个MRJobLauncher用来launch和run Gobblin Job的流程是:
创建一个Source实例对象,获得WorkUnit
把workUnit序列化成HDFS上的文件。
再搞一个文件把上述2中文件的路径存一下。
新建一个Map Job把3中的文件(所有workUnit路径)当成input
启动Map Job
完成后,收集task状态信息到state store,并publish 抽取到的数据
一个Maper可以执行一个或多个task, 如果 的Gobblin job配置文件中对maper数量没有限制,那么默认一个workunit一个task,对应一个mapper; 如果设置的mapper数量不够,就会出现一个map多个workunit。Gobblin 还有一个MutiWorkUnit 可以控制多个workunit一起被mapper执行。
MR模式部署
Usage: gobblin-mapreduce.sh [OPTION] --conf <job configuration file>
Where OPTION can be:
–jt
–fs
–jars
–workdir
–help Display this help and exit
conf/gobblin-mapreduce.properties中的fs.uri制定Gobblin使用的Hdfs路径
fs.uri=hdfs://
-fs也可制定uri,单应该跟fs.uri不冲突
所有的数据和状态信息都会存在这里,一定要保证HADOOP_BIN_DIR环境变量已经设置好
GOBBLIN_WORK_DIR或者–workdir也应该指定在uri下