
Gobblin是Linkedin内部用来整合各种数据源(关系型数据库,kafka,FTP/SFTP servers等等)通用ETL框架,于14年开源(地址)。用本人低俗的理解,画了一张很大的饼,各种数据都可以在这里“一站式”解决ETL整个过程(据说他们内部也是这么干的),专为大数据而生。
在某道公司实习的时候参与到一个实时统计系统的优化,之前日志数据从Kafka到Hdfs的落地用的是Linkedin/camus,但据说作者不想写了(也有人说写到太烂了,,),现在已经停止开发,借助Hdfs上由Avro改Parquet列式存储的机会,把camus替换成了Gobblin,花了一段时间了解Gobblin。
论文的阅读理解和整体架构稍后再写吧,这次先借助官方Wiki的Kafka-Hdfs case study,从自己接触最多的部分开始介绍吧。
作为一个通用框架,Gobblin的接口封装和概念抽象做的很好,作为一个ETL框架使用者,基本地,我们只需要实现我们自己的Source,Extractor,Conventer类,再加上一些源-目的地址之类的通过配置文件提交给Gobblin就行了,当然Gobblin已经为我们实现了很多类,可以直接拿来用,比如针对Kafka的KafkaExtractor,KafkaSource,KafkaAvroSource(肯定少不了为Avro定制的东西,,)。不过Gobblin强大的地方还在于,还可以让用户定制更多的东西,比如QualitlyChecker,Writer,Publisher等,还支持Compaction去重和小文件的merge。
流程
下面结合Gobblin文章中的流程图和源码中提供的Kafka-Hdfs的基础类,先分析下整体流程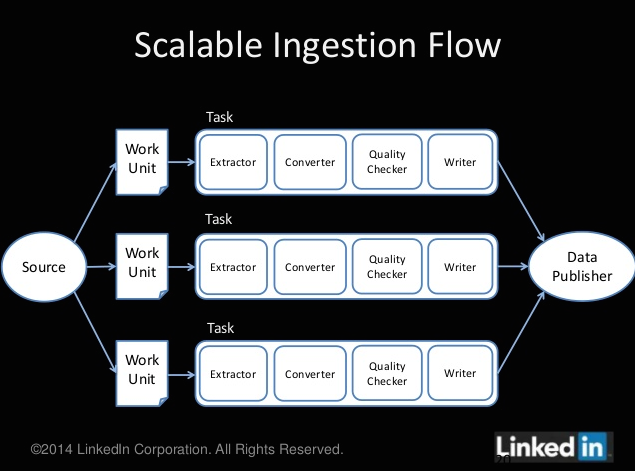
- 配置文件指定我们的Source,Writer等类,和地址等,配置文件后缀名必须是.job或者.pull
- 脚本启动,可以选Standalone和MR两种模式,通过参数或者环境变量指定一些工作目录详见[Wiki/Deployment]
- gobblin-runtime包下的JobLauncher读取配置文件,将配置文件抽象成一种SourceState结构,
将SourceStare交给我们的KafaSource。Source类要做的跟数据源取得联系,比如初始化一些metadata元数据等,并生成WorkUnit(这个概念是为了迎合Yarn中Container的概念,并且可以指定配置一些策略如通过指定mapper数量修改对应关系,默认一个WorkUnit一个mapper,),然后把WorkUnit交给JobManager来调度, gobblin-core包下自带的关于kafka的类见下图:
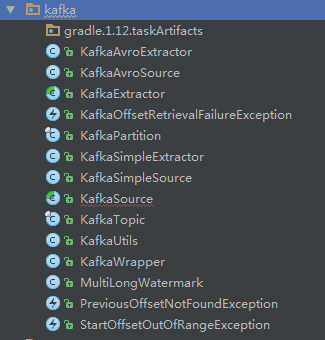
这里必须提一下KafkaWraper,这里封装了各种跟kafka打交道的api,不过截至目前都是用的old api,新api的接口函数以及有了,但是没有实现,调用会直接throw异常。Extractor负责实现从数据源中读数据。
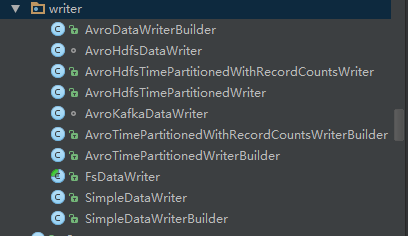
- 后面就是经过Converter和qualityChecker对数据做一些转换和校验,然后根据配置文件指定,选择writer写入本地文件或者HDFS,gobblin-core提供simple、Avro和fs三类writer,详见下图并针对Hdfs提供可根据时间切割文件的类。
接口
Source类需要实现两个函数: getWorkUnits,和getExtractor
public List<WorkUnit> getWorkunits(SourceState state){}
根据解析出来的配置文件生成WorkUnit,这个在KafkaSource类中实现,但是KafkaSource还是抽象类,core包自带两个实现类,KafkaAvroSource和KafkaSimpleSource类public Extractor
return new KafkaAvroExtractor(state);
}
KafkaAvroSource类就是产生一个Extractor,WorkUnit产生之后在被调度时会加上一些状态量比如
WorkUnitState workUnitState = new WorkUnitState(workUnit);
workUnitState.setId(taskId);
workUnitState.setProp(ConfigurationKeys.JOB_ID_KEY, jobId);
workUnitState.setProp(ConfigurationKeys.TASK_ID_KEY, taskId);
this.workUnitManager.addWorkUnit(workUnitState);
被JobManeger调度的时候会根据WorkUnitState从getExtractor接口拿到一个Extractor句柄,来真正抽取数据。
Extractor类需要实现的函数较多,最主要的还是readRecordImpl,不过core提供的KafkaExtractor还是抽象类,需要我们另外实现一个函数
D decodeRecord(MessageAndOffset messageAndOffset);
即解码kafka的MessageAndOffset对象